一 java基础知识
1.1 基础内存分配
String a="aaaa"; |
二 多线程知识
2.1 创建线程池
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, |
参数
corePoolSize- 即使空闲时仍保留在池中的线程数,除非设置allowCoreThreadTimeOutmaximumPoolSize- 池中允许的最大线程数keepAliveTime- 当线程数大于内核时,这是多余的空闲线程在终止前等待新任务的最大时间。unit-keepAliveTime参数的时间单位workQueue- 用于在执行任务之前使用的队列。 这个队列将仅保存execute方法提交的Runnable任务。threadFactory- 执行程序创建新线程时使用的工厂handler- 执行被阻止时使用的处理程序,因为达到线程限制和队列容量
异常
IllegalArgumentException- 如果以下某项成立:corePoolSize < 0keepAliveTime < 0maximumPoolSize <= 0maximumPoolSize < corePoolSizeNullPointerException- 如果workQueue或threadFactory或handler为空
拒绝策略
static class |
ThreadPoolExecutor.AbortPolicy 被拒绝的任务的处理程序,抛出一个 RejectedExecutionException 。 |
|---|---|
static class |
ThreadPoolExecutor.CallerRunsPolicy 一个被拒绝的任务的处理程序,直接在 execute方法的调用线程中运行被拒绝的任务,除非执行程序已经被关闭,否则这个任务被丢弃。 |
static class |
ThreadPoolExecutor.DiscardOldestPolicy 被拒绝的任务的处理程序,丢弃最旧的未处理请求,然后重试 execute ,除非执行程序关闭,在这种情况下,任务被丢弃。 |
static class |
ThreadPoolExecutor.DiscardPolicy 被拒绝的任务的处理程序静默地丢弃被拒绝的任务。 |
排队
任何BlockingQueue可用于传送和保留提交的任务。 这个队列的使用与池大小相互作用:
- 如果少于corePoolSize线程正在运行,Executor总是喜欢添加一个新线程,而不是排队。
- 如果corePoolSize或更多的线程正在运行,Executor总是喜欢排队请求而不是添加一个新的线程。
如果请求无法排队,则会创建一个新线程,除非这将超出maximumPoolSize,否则任务将被拒绝。
排队有三种一般策略:
直接切换
一个工作队列的一个很好的默认选择是一个
SynchronousQueue,将任务交给线程,无需另外控制。 在这里,如果没有线程可以立即运行,那么尝试排队任务会失败,因此将构建一个新的线程。 处理可能具有内部依赖关系的请求集时,此策略可避免锁定。 直接切换通常需要无限制的maximumPoolSizes,以避免拒绝新提交的任务。 这反过来允许无限线程增长的可能性,当命令继续以平均速度比他们可以处理的速度更快地到达时。
无界队列
使用无界队列(例如
LinkedBlockingQueue没有预定容量)会导致新的任务,在队列中等待,当所有corePoolSize线程都很忙。 因此,不会再创建corePoolSize线程。 (因此,最大值大小的值没有任何影响。)每个任务完全独立于其他任务时,这可能是适当的,因此任务不会影响其他执行; 例如,在网页服务器中。 虽然这种排队风格可以有助于平滑瞬态突发的请求,但是当命令继续达到的平均速度比可以处理的速度更快时,它承认无界工作队列增长的可能性。 有边界的队列。
有限队列
(例如,
ArrayBlockingQueue)有助于在使用有限maxPoolSizes时防止资源耗尽,但可能更难调整和控制。 队列大小和最大池大小可能彼此交易:使用大队列和小型池可以最大限度地减少CPU使用率,OS资源和上下文切换开销,但可能导致人为的低吞吐量。 如果任务频繁阻塞(例如,如果它们是I / O绑定),则系统可能能够安排比您允许的更多线程的时间。 使用小型队列通常需要较大的池大小,这样可以使CPU繁忙,但可能会遇到不可接受的调度开销,这也降低了吞吐量。
所有已知实现类:
ArrayBlockingQueue , DelayQueue , LinkedBlockingDeque , LinkedBlockingQueue , LinkedTransferQueue , PriorityBlockingQueue , SynchronousQueue
Queue另外支持在检索元素时等待队列变为非空的操作,并且在存储元素时等待队列中的空间变得可用。BlockingQueue方法有四种形式,具有不同的操作方式,不能立即满足,但可能在将来的某个时间点满足:一个抛出异常,第二个返回一个特殊值(null或false,具体取决于操作),第三个程序将无限期地阻止当前线程,直到操作成功为止,而第四个程序块在放弃之前只有给定的最大时限。 这些方法总结在下表中:BlockingQueue不接受null元素。 实现抛出NullPointerException上尝试add,put或offer一个null。 Anull用作哨兵值以指示poll操作失败。BlockingQueue可能是容量有限的。 在任何给定的时间它可能有一个remainingCapacity超过其中没有额外的元素可以put没有阻止。 没有任何内在容量限制的ABlockingQueue总是报告剩余容量为Integer.MAX_VALUE。BlockingQueue实现被设计为主要用于生产者 - 消费者队列,但另外支持Collection接口。 因此,例如,可以使用remove(x)从队列中删除任意元素。 然而,这样的操作通常不能非常有效地执行,并且仅用于偶尔使用,例如当排队的消息被取消时。BlockingQueue实现是线程安全的。 所有排队方法使用内部锁或其他形式的并发控制在原子上实现其效果。 然而, 大量的Collection操作addAll,containsAll,retainAll和removeAll不一定原子除非在实现中另有规定执行。 因此有可能,例如,为addAll(c)到只增加一些元件在后失败(抛出异常)c。BlockingQueue上不支持任何类型的“关闭”或“关闭”操作,表示不再添加项目。 这些功能的需求和使用往往依赖于实现。 例如,一个常见的策略是生产者插入特殊的尾流或毒物 ,这些消费者在被消费者摄取时被相应地解释。
2.2 线程池常见问题
【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
CachedThreadPool 的定义为
public static ExecutorService newCachedThreadPool() { |
2.3 sleep 与 wait 区别
- 对于 sleep()方法,我们首先要知道该方法是属于 Thread 类中的。而 wait()方法,则是属于Object 类中的
- sleep()方法导致了程序暂停执行指定的时间,让出 cpu 该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。
- 在调用 sleep()方法的过程中,线程不会释放对象锁。
- 而当调用 wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用 notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
四 spring 相关知识点
4.1 spring 的生命周期
- Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
- Bean实例化后对将Bean的引入和值注入到Bean的属性中
- 如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
- 如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
- 如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来。
- 如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
- 如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
- 如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
- 此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
- 如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
4.2 spring的作用域
Spring 容器在初始化一个 Bean 的实例时,同时会指定该实例的作用域。Spring3 为 Bean 定义了五种作用域,具体如下。
1)singleton
单例模式,使用 singleton 定义的 Bean 在 Spring 容器中只有一个实例,这也是 Bean 默认的作用域。
2)prototype
原型模式,每次通过 Spring 容器获取 prototype 定义的 Bean 时,容器都将创建一个新的 Bean 实例。
3)request
在一次 HTTP 请求中,容器会返回该 Bean 的同一个实例。而对不同的 HTTP 请求,会返回不同的实例,该作用域仅在当前 HTTP Request 内有效。
4)session
在一次 HTTP Session 中,容器会返回该 Bean 的同一个实例。而对不同的 HTTP 请求,会返回不同的实例,该作用域仅在当前 HTTP Session 内有效。
5)global Session
在一个全局的 HTTP Session 中,容器会返回该 Bean 的同一个实例。该作用域仅在使用 portlet context 时有效。
五 事物的传播与隔离
5.1 问题
5.1.1 脏读
所谓脏读是指一个事务中访问到了另外一个事务未提交的数据,具体来说假如有两个事务A和B同时更新一个数据d=1,事务B先执行了select获取到d=1,然后更新d=2但是没有提交,这时候事务A在B没有提交的情况下执行搜索结果d=2,这就是脏读。
5.1.2 不可重复读
所谓不可重复读是指一个事务内在未提交的前提下多次搜索一个数据,搜出来的结果不一致。发生不可重复读的原因是在多次搜索期间这个数据被其他事务更新了。
5.1.3 幻读
所谓幻读是指同一个事务内多次查询(注意查询的sql不一定一样)返回的结果集的不一样(比如新增或者少了一条数据),比如同一个事务A内第一次查询时候有n条记录,但是第二次同等条件下查询却又n+1条记录,这就好像产生了幻觉,为啥两次结果不一样那。其实和不可重复读一样,发生幻读的原因也是另外一个事务新增或者删除或者修改了第一个事务结果集里面的数据。不同在于不可重复读是数据内容被修改了,幻读是数据变多了或者少了。
5.2 事务的几种传播特性
事务的传播性一般在事务嵌套时候使用,比如在事务A里面调用了另外一个使用事务的方法,那么这俩个事务是各自作为独立的事务执行提交,还是内层的事务合并到外层的事务一块提交那,这就是事务传播性要确定的问题。下面一一介绍比较常用的事务传播性。
PROPAGATION_REQUIRED: 如果存在一个事务,则支持当前事务。如果没有事务则开启
PROPAGATION_SUPPORTS: 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行
PROPAGATION_MANDATORY: 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
PROPAGATION_REQUIRES_NEW: 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
PROPAGATION_NOT_SUPPORTED: 总是非事务地执行,并挂起任何存在的事务。
PROPAGATION_NEVER: 总是非事务地执行,如果存在一个活动事务,则抛出异常
PROPAGATION_NESTED: 如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务,
则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行
5.3 事务的隔离级别
事务的隔离性是指多个事务并发执行的时候相互之间不受到彼此的干扰,是事务acid中i,根据隔离程度对隔离性有会分类。在具体介绍事务隔离性前有必要介绍几个名词说明数据库并发操作存在的问题。
ISOLATION_DEFAULT: 默认隔离级别,这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应
ISOLATION_READ_UNCOMMITTED: 读未提交 ,这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻像读。
ISOLATION_READ_COMMITTED: 读已提交 , 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
ISOLATION_REPEATABLE_READ: 重复读取, 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
ISOLATION_SERIALIZABLE , 串行化,这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
除了防止脏读,不可重复读外,还避免了幻像读。
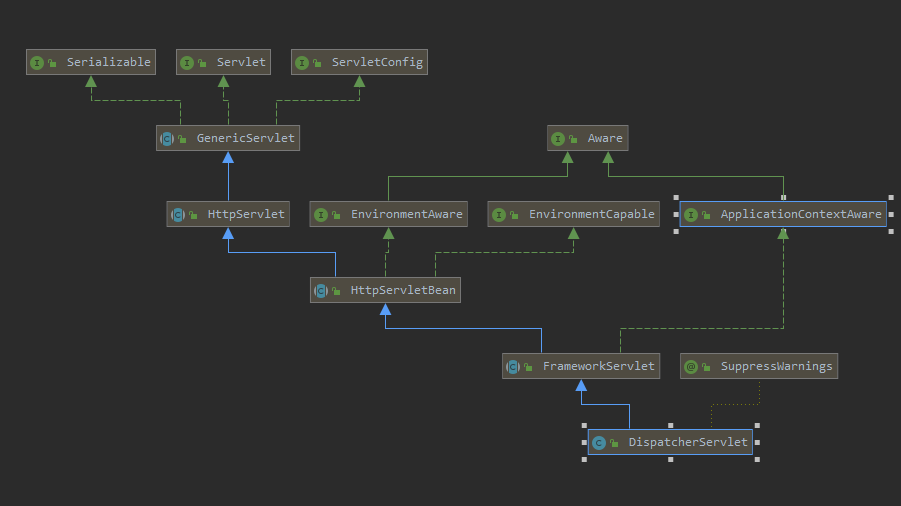
六 springmvc
- 第一步:发起请求到前端控制器(DispatcherServlet)
- 第二步:前端控制器请求HandlerMapping查找 Handler (可以根据xml配置、注解进行查找)
- 第三步:处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略
- 第四步:前端控制器调用处理器适配器去执行Handler
- 第五步:处理器适配器HandlerAdapter将会根据适配的结果去执行Handler
- 第六步:Handler执行完成给适配器返回ModelAndView
- 第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)
- 第八步:前端控制器请求视图解析器去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
- 第九步:视图解析器向前端控制器返回View
- 第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
第十一步:前端控制器向用户响应结果
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception { |
七 数据库相关
7.1 expain命令详解
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
-- 实际SQL,查找用户名为Jefabc的员工 |
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
概要描述:
- id:选择标识符
- select_type:表示查询的类型。
- table:输出结果集的表
- partitions:匹配的分区
- type:表示表的连接类型
- possible_keys:表示查询时,可能使用的索引
- key:表示实际使用的索引
- key_len:索引字段的长度
- ref:列与索引的比较
- rows:扫描出的行数(估算的行数)
- filtered:按表条件过滤的行百分比
- Extra:执行情况的描述和说明
下面对这些字段出现的可能进行解释:
7.1.1 id
SELECT识别符。这是SELECT的查询序列号
我的理解是SQL执行的顺序的标识,SQL从大到小的执行
id相同时,执行顺序由上至下
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
-- 查看在研发部并且名字以Jef开头的员工,经典查询 |
7.1.2 select_type
示查询中每个select子句的类型
SIMPLE(简单SELECT,不使用UNION或子查询等)
PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
UNION(UNION中的第二个或后面的SELECT语句)
DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
DERIVED(派生表的SELECT, FROM子句的子查询)
UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
7.1.3 table
显示这一步所访问数据库中表名称(显示这一行的数据是关于哪张表的),有时不是真实的表名字,可能是简称,例如上面的e,d,也可能是第几步执行的结果的简称
7.1.4 type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
7.1.5 possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
7.1.6 Key
key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
7.1.7 key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
不损失精确性的情况下,长度越短越好
7.1.8 ref
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
7.1.9 rows
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
7.1.10 Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
-- 测试Extra的filesort |
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
-- explain select now() from dual; |
总结
• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
• EXPLAIN不考虑各种Cache
• EXPLAIN不能显示MySQL在执行查询时所作的优化工作
• 部分统计信息是估算的,并非精确值
• EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划
7.2 索引失效
- like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效。
- or语句前后没有同时使用索引。当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效
- 组合索引,不是使用第一列索引,索引失效。
- 数据类型出现隐式转化。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描。
- 在索引列上使用 IS NULL 或 IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可。
- 在索引字段上使用not,<>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0。
- 对索引字段进行计算操作、在字段上使用函数。(索引为 emp(ename,empno,sal))
- 当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效。
7.3 数据库锁
MyISAM支持表锁,InnoDB支持表锁和行锁,默认为行锁
表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量最低
行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高
7.4 存储过程
我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
一个存储过程是一个可编程的函数,它在数据库中创建并保存。它可以有SQL语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。
优点:
存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
存储过程允许标准组件是编程。存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
存储过程能实现较快的执行速度。如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
存储过程能过减少网络流量。针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
存储过程可被作为一种安全机制来充分利用。系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
7.5 数据库查询
不要使用 count(列名)或 count(常量)来替代 count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
八 生命周期
8.1 vue生命周期

九 MQ相关
9.1 丢消息怎么办
这得从java的java.net.SocketException异常说起。简单点说就是当网络发送方发送一堆数据,然后调用close关闭连接之后。这些发送的数据都在接收者的缓存里,接收者如果调用read方法仍旧能从缓存中读取这些数据,尽管对方已经关闭了连接。但是当接收者尝试发送数据时,由于此时连接已关闭,所以会发生异常,这个很好理解。不过需要注意的是,当发生SocketException后,原本缓存区中数据也作废了,此时接收者再次调用read方法去读取缓存中的数据,就会报Software caused connection abort: recv failed错误。
通过抓包得知,ActiveMQ会每隔10秒发送一个心跳包,这个心跳包是服务器发送给客户端的,用来判断客户端死没死。如果你看过上面第一条,就会知道非持久化消息堆积到一定程度会写到文件里,这个写的过程会阻塞所有动作,而且会持续20到30秒,并且随着内存的增大而增大。当客户端发完消息调用connection.close()时,会期待服务器对于关闭连接的回答,如果超过15秒没回答就直接调用socket层的close关闭tcp连接了。这时客户端发出的消息其实还在服务器的缓存里等待处理,不过由于服务器心跳包的设置,导致发生了java.net.SocketException异常,把缓存里的数据作废了,没处理的消息全部丢失。
解决方案:用持久化消息,或者非持久化消息及时处理不要堆积,或者启动事务,启动事务后,commit()方法会负责任的等待服务器的返回,也就不会关闭连接导致消息丢失了。
9.2 持久化消息非常慢。
默认的情况下,非持久化的消息是异步发送的,持久化的消息是同步发送的,遇到慢一点的硬盘,发送消息的速度是无法忍受的。但是在开启事务的情况下,消息都是异步发送的,效率会有2个数量级的提升。所以在发送持久化消息时,请务必开启事务模式。其实发送非持久化消息时也建议开启事务,因为根本不会影响性能。
9.3 消息的不均匀消费
有时在发送一些消息之后,开启2个消费者去处理消息。会发现一个消费者处理了所有的消息,另一个消费者根本没收到消息。原因在于ActiveMQ的prefetch机制。当消费者去获取消息时,不会一条一条去获取,而是一次性获取一批,默认是1000条。这些预获取的消息,在还没确认消费之前,在管理控制台还是可以看见这些消息的,但是不会再分配给其他消费者,此时这些消息的状态应该算作“已分配未消费”,如果消息最后被消费,则会在服务器端被删除,如果消费者崩溃,则这些消息会被重新分配给新的消费者。但是如果消费者既不消费确认,又不崩溃,那这些消息就永远躺在消费者的缓存区里无法处理。更通常的情况是,消费这些消息非常耗时,你开了10个消费者去处理,结果发现只有一台机器吭哧吭哧处理,另外9台啥事不干。
解决方案:将prefetch设为1,每次处理1条消息,处理完再去取,这样也慢不了多少。
9.4 死信队列
如果你想在消息处理失败后,不被服务器删除,还能被其他消费者处理或重试,可以关闭AUTO_ACKNOWLEDGE,将ack交由程序自己处理。那如果使用了AUTO_ACKNOWLEDGE,消息是什么时候被确认的,还有没有阻止消息确认的方法?有!
消费消息有2种方法,一种是调用consumer.receive()方法,该方法将阻塞直到获得并返回一条消息。这种情况下,消息返回给方法调用者之后就自动被确认了。另一种方法是采用listener回调函数,在有消息到达时,会调用listener接口的onMessage方法。在这种情况下,在onMessage方法执行完毕后,消息才会被确认,此时只要在方法中抛出异常,该消息就不会被确认。那么问题来了,如果一条消息不能被处理,会被退回服务器重新分配,如果只有一个消费者,该消息又会重新被获取,重新抛异常。就算有多个消费者,往往在一个服务器上不能处理的消息,在另外的服务器上依然不能被处理。难道就这么退回—获取—报错死循环了吗?
在重试6次后,ActiveMQ认为这条消息是“有毒”的,将会把消息丢到死信队列里。如果你的消息不见了,去ActiveMQ.DLQ里找找,说不定就躺在那里。
9.5 什么是RabbitMQ
答:RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的,消息中间件;
可以用它来:解耦、异步、削峰。
9.6 如何保证RabbitMQ消息的可靠传输?
答:消息不可靠的情况可能是消息丢失,劫持等原因;
丢失又分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息;
生产者丢失消息:从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息;
transaction机制就是说:发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit())。然而,这种方式有个缺点:吞吐量下降;
confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;
rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;
如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
消息队列丢数据:消息持久化。
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。
这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢?
这里顺便说一下吧,其实也很容易,就下面两步
- 将queue的持久化标识durable设置为true,则代表是一个持久的队列
- 发送消息的时候将deliveryMode=2
这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据
消费者丢失消息:消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可!
消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消息;
如果这时处理消息失败,就会丢失该消息;
解决方案:处理消息成功后,手动回复确认消息。
9.7 RabbitMQ 概念
RabbitMQ 概念里的 channel、exchange 和 queue 是逻辑概念,还是对应着进程实体?分别起什么作用?
queue 具有自己的 erlang 进程;exchange 内部实现为保存 binding 关系的查找表;channel 是实际进行路由工作的实体,即负责按照 routing_key 将 message 投递给 queue 。由 AMQP 协议描述可知,channel 是真实 TCP 连接之上的虚拟连接,所有 AMQP 命令都是通过 channel 发送的,且每一个 channel 有唯一的 ID。一个 channel 只能被单独一个操作系统线程使用,故投递到特定 channel 上的 message 是有顺序的。但一个操作系统线程上允许使用多个 channel 。
9.8 vhost 是什么?起什么作用
vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
9.9 消息怎么路由
从概念上来说,消息路由必须有三部分:交换器、路由、绑定。生产者把消息发布到交换器上;绑定决定了消息如何从路由器路由到特定的队列;消息最终到达队列,并被消费者接收。
- 消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。
- 通过队列路由键,可以把队列绑定到交换器上。
- 消息到达交换器后,RabbitMQ会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则)。如果能够匹配到队列,则消息会投递到相应队列中;如果不能匹配到任何队列,消息将进入 “黑洞”。
常用的交换器主要分为一下三种:
- direct:如果路由键完全匹配,消息就被投递到相应的队列
- fanout:如果交换器收到消息,将会广播到所有绑定的队列上
- topic:可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符,比如:“*” 匹配特定位置的任意文本, “.” 把路由键分为了几部分,“#” 匹配所有规则等。特别注意:发往topic交换器的消息不能随意的设置选择键(routing_key),必须是由”.”隔开的一系列的标识符组成。
9.10 如何确保消息正确地发送至RabbitMQ?
RabbitMQ使用发送方确认模式,确保消息正确地发送到RabbitMQ。发送方确认模式:将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(not acknowledged,未确认)消息。发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
9.11 如何确保消息接收方消费了消息
接收方消息确认机制:消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。
下面罗列几种特殊情况:
- 如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要根据bizId去重)
- 如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,将不会给该消费者分发更多的消息。
9.12 如何避免消息重复投递或重复消费
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列;在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重和幂等的依据,避免同一条消息被重复消费。
这个问题针对业务场景来答分以下几点:
1.比如,你拿到这个消息做数据库的insert操作。那就容易了,给这个消息做一个唯一主键,那么就算出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
2.再比如,你拿到这个消息做redis的set的操作,那就容易了,不用解决,因为你无论set几次结果都是一样的,set操作本来就算幂等操作。
3.如果上面两种情况还不行,上大招。准备一个第三方介质,来做消费记录。以redis为例,给消息分配一个全局id,只要消费过该消息,将
9.13 死信队列和延迟队列的使用
死信消息:
- 消息被拒绝(Basic.Reject或Basic.Nack)并且设置 requeue 参数的值为 false
- 消息过期了
- 队列达到最大的长度
过期消息:
在 rabbitmq 中存在2种方可设置消息的过期时间,第一种通过对队列进行设置,这种设置后,该队列中所有的消息都存在相同的过期时间,第二种通过对消息本身进行设置,那么每条消息的过期时间都不一样。如果同时使用这2种方法,那么以过期时间小的那个数值为准。当消息达到过期时间还没有被消费,那么那个消息就成为了一个 死信 消息。
队列设置 : 在队列申明的时候使用 x-message-ttl 参数,单位为 毫秒
单个消息设置 : 是设置消息属性的 expiration 参数的值,单位为 毫秒
延时队列:在rabbitmq中不存在延时队列,但是我们可以通过设置消息的过期时间和死信队列来模拟出延时队列。消费者监听死信交换器绑定的队列,而不要监听消息发送的队列。
十 zookeeper相关知识
10.1 节点类型
永久节点,永久有序节点,临时节点、临时有序节点
10.2 zookeeper是如何保证事务的顺序一致性的
zookeeper采用了递增的事务Id来标识,所有的proposal都在被提出的时候加上了zxid,zxid实际上是一个64位的数字,高32位是epoch用来标识leader是否发生改变,如果有新的leader产生出来,epoch会自增,低32位用来递增计数。当新产生proposal的时候,会依据数据库的两阶段过程,首先会向其他的server发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行
10.3 zookeeper是如何选取主leader的?
当leader崩溃或者leader失去大多数的follower,这时zk进入恢复模式,
10.4 zk的配置管理
程序分布式的部署在不同的机器上,将程序的配置信息放在zk的znode下,当有配置发生改变时,也就是znode发生变化时,可以通过改变zk中某个目录节点的内容,利用water通知给各个客户端 从而更改配置。
10.5 机器中为什么会有master
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,于是就需要进行master选举。
10.6 ZK选举过程
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法使用ZAB协议:
选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
选举线程首先向所有Server发起一次询问(包括自己);
选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
10.7 节点变多时,PtBalancer速度变慢
类似问题:根据Netflix的Curator作者所说,ZooKeeper真心不适合做Queue,或者说ZK没有实现一个好的Queue,详细内容可以看https://cwiki.apache.org/confluence/display/CURATOR/TN4,
原因有五:
- ZK有1MB 的传输限制。 实践中ZNode必须相对较小,而队列包含成千上万的消息,非常的大。
- 如果有很多节点,ZK启动时相当的慢。 而使用queue会导致好多ZNode. 你需要显著增大 initLimit 和 syncLimit.
- ZNode很大的时候很难清理。Netflix不得不创建了一个专门的程序做这事。
- 当很大量的包含成千上万的子节点的ZNode时, ZK的性能变得不好
ZK的数据库完全放在内存中。 大量的Queue意味着会占用很多的内存空间。
尽管如此, Curator还是创建了各种Queue的实现。 如果Queue的数据量不太多,数据量不太大的情况下,酌情考虑,还是可以使用的。
10.8 客户端如何处理异常
客户端如何正确处理CONNECTIONLOSS(连接断开) 和 SESSIONEXPIRED(Session 过期)两类连接异常
在ZooKeeper中,服务器和客户端之间维持的是一个长连接,在 SESSION_TIMEOUT 时间内,服务器会确定客户端是否正常连接(客户端会定时向服务器发送heart_beat),服务器重置下次SESSION_TIMEOUT时间。因此,在正常情况下,Session一直有效,并且zk集群所有机器上都保存这个Session信息。在出现问题情况下,客户端与服务器之间连接断了(客户端所连接的那台zk机器挂了,或是其它原因的网络闪断),这个时候客户端会主动在地址列表(初始化的时候传入构造方法的那个参数connectString)中选择新的地址进行连接。
好了,上面基本就是服务器与客户端之间维持长连接的过程了。在这个过程中,用户可能会看到两类异常CONNECTIONLOSS(连接断开) 和SESSIONEXPIRED(Session 过期)。
CONNECTIONLOSS发生在上面红色文字部分,应用在进行操作A时,发生了CONNECTIONLOSS,此时用户不需要关心我的会话是否可用,应用所要做的就是等待客户端帮我们自动连接上新的zk机器,一旦成功连接上新的zk机器后,确认刚刚的操作A是否执行成功了。
10.9 是否实时数据更新
一个客户端修改了某个节点的数据,其它客户端能够马上获取到这个最新数据吗
ZooKeeper不能确保任何客户端能够获取(即Read Request)到一样的数据,除非客户端自己要求:方法是客户端在获取数据之前调用org.apache.zookeeper.AsyncCallback.VoidCallback, java.lang.Object) sync.
通常情况下(这里所说的通常情况满足:1. 对获取的数据是否是最新版本不敏感,2. 一个客户端修改了数据,其它客户端是否需要立即能够获取最新),可以不关心这点。
在其它情况下,最清晰的场景是这样:ZK客户端A对 /my_test 的内容从 v1->v2, 但是ZK客户端B对 /my_test 的内容获取,依然得到的是 v1. 请注意,这个是实际存在的现象,当然延时很短。解决的方法是客户端B先调用 sync(), 再调用 getData().
10.10 ZK为什么不提供一个永久性的Watcher注册机制
不支持用持久Watcher的原因很简单,ZK无法保证性能。
使用watch需要注意的几点
- Watches通知是一次性的,必须重复注册.
- 发生CONNECTIONLOSS之后,只要在session_timeout之内再次连接上(即不发生SESSIONEXPIRED),那么这个连接注册的watches依然在。
- 节点数据的版本变化会触发NodeDataChanged,注意,这里特意说明了是版本变化。存在这样的情况,只要成功执行了setData()方法,无论内容是否和之前一致,都会触发NodeDataChanged。
- 对某个节点注册了watch,但是节点被删除了,那么注册在这个节点上的watches都会被移除。
- 同一个zk客户端对某一个节点注册相同的watch,只会收到一次通知。
- Watcher对象只会保存在客户端,不会传递到服务端。
10.11 是否实时节点删除
创建的临时节点什么时候会被删除,是连接一断就删除吗?延时是多少?
连接断了之后,ZK不会马上移除临时数据,只有当SESSIONEXPIRED之后,才会把这个会话建立的临时数据移除。因此,用户需要谨慎设置Session_TimeOut
10.12 节点之间通信
ZooKeeper集群中服务器之间是怎样通信的?
Leader服务器会和每一个Follower/Observer服务器都建立TCP连接,同时为每个F/O都创建一个叫做LearnerHandler的实体。LearnerHandler主要负责Leader和F/O之间的网络通讯,包括数据同步,请求转发和Proposal提议的投票等。Leader服务器保存了所有F/O的LearnerHandler。
10.12 日志清理
zookeeper是否会自动进行日志清理?如何进行日志清理?
zk自己不会进行日志清理,需要运维人员进行日志清理
10.13 节点通知
在getChildren(String path, boolean watch)是注册了对节点子节点的变化,那么子节点的子节点变化能通知吗
不能
十一 分布式锁
11.1 线程锁定义
11.1.1 悲观锁/乐观锁
悲观锁
正如其名,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
悲观锁主要分为共享锁或排他锁
- 共享锁【Shared lock】又称为读锁,简称S锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁【Exclusive lock】又称为写锁,简称X锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据行读取和修改。
乐观锁
乐观锁机制采取了更加宽松的加锁机制。乐观锁是相对悲观锁而言,也是为了避免数据库幻读、业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。
相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
11.1.2 公平锁/非公平锁
公平锁
- 公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁
- 非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
11.1.3 可重入锁
可重入锁也叫递归锁,它俩等同于一回事,指的是同一线程外层函数获得锁之后,内层递归函数仍然能获得该锁的代码,同一线程在外层方法获取锁的时候,再进入内层方法会自动获取锁。也就是说,线程可以进入任何一个它已经拥有的锁所同步着的代码块。ReentrantLock 和 synchronized 就是典型的可重入锁!
11.1.4 自旋锁
自旋锁是一种互斥锁的实现方式而已,相比一般的互斥锁会在等待期间放弃cpu,自旋锁(spinlock)则是不断循环并测试锁的状态,这样就一直占着cpu。
互斥锁:用于保护临界区,确保同一时间只有一个线程访问数据。对共享资源的访问,先对互斥量进行加锁,如果互斥量已经上锁,调用线程会阻塞,直到互斥量被解锁。在完成了对共享资源的访问后,要对互斥量进行解锁。
临界区:每个进程中访问临界资源的那段程序称为临界区,每次只允许一个进程进入临界区,进入后不允许其他进程进入。
自旋锁:与互斥量类似,它不是通过休眠使进程阻塞,而是在获取锁之前一直处于忙等(自旋)阻塞状态。用在以下情况:锁持有的时间短,而且线程并不希望在重新调度上花太多的成本。”原地打转”。
自旋锁与互斥锁的区别:线程在申请自旋锁的时候,线程不会被挂起,而是处于忙等的状态。
11.1.5 信号量
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
11.3 redis锁
11. 3.1 使用redis的setnx()、expire()方法,用于分布式锁
对于使用redis的setnx()、expire()来实现分布式锁,这个方案相对于memcached()的add()方案,redis占优势的是,其支持的数据类型更多,而memcached只支持String一种数据类型。除此之外,无论是从性能上来说,还是操作方便性来说,其实都没有太多的差异,完全看你的选择,比如公司中用哪个比较多,你就可以用哪个。
首先说明一下setnx()命令,setnx的含义就是SET if Not Exists,其主要有两个参数 setnx(key, value)。该方法是原子的,如果key不存在,则设置当前key成功,返回1;如果当前key已经存在,则设置当前key失败,返回0。但是要注意的是setnx命令不能设置key的超时时间,只能通过expire()来对key设置。
具体的使用步骤如下:
- setnx(lockkey, 1) 如果返回0,则说明占位失败;如果返回1,则说明占位成功
- expire()命令对lockkey设置超时时间,为的是避免死锁问题。
执行完业务代码后,可以通过delete命令删除key。
这个方案其实是可以解决日常工作中的需求的,但从技术方案的探讨上来说,可能还有一些可以完善的地方。比如,如果在第一步setnx执行成功后,在expire()命令执行成功前,发生了宕机的现象,那么就依然会出现死锁的问题,所以如果要对其进行完善的话,可以使用redis的setnx()、get()和getset()方法来实现分布式锁。
11.3.2 使用redis的setnx()、get()、getset()方法,用于分布式锁:
这个方案的背景主要是在setnx()和expire()的方案上针对可能存在的死锁问题,做了一版优化。
那么先说明一下这三个命令,对于setnx()和get()这两个命令,相信不用再多说什么。那么getset()命令?这个命令主要有两个参数 getset(key,newValue)。该方法是原子的,对key设置newValue这个值,并且返回key原来的旧值。假设key原来是不存在的,那么多次执行这个命令,会出现下边的效果:
getset(key, “value1”) 返回nil 此时key的值会被设置为value1
getset(key, “value2”) 返回value1 此时key的值会被设置为value2
依次类推!
介绍完要使用的命令后,具体的使用步骤如下:
- setnx(lockkey, 当前时间+过期超时时间) ,如果返回1,则获取锁成功;如果返回0则没有获取到锁,转向2。
- get(lockkey)获取值oldExpireTime ,并将这个value值与当前的系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取,转向3。
- 计算newExpireTime=当前时间+过期超时时间,然后getset(lockkey, newExpireTime) 会返回当前lockkey的值currentExpireTime。
- 判断currentExpireTime与oldExpireTime 是否相等,如果相等,说明当前getset设置成功,获取到了锁。如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回失败,或者继续重试。
- 在获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行delete释放锁;如果大于锁设置的超时时间,则不需要再锁进行处理。
问题1: 在“get(lockkey)获取值oldExpireTime ”这个操作与“getset(lockkey, newExpireTime) ”这个操作之间,如果有N个线程在get操作获取到相同的oldExpireTime后,然后都去getset,会不会返回的newExpireTime都是一样的,都会是成功,进而都获取到锁???
问题2: 在“get(lockkey)获取值oldExpireTime ”这个操作与“getset(lockkey, newExpireTime) ”这个操作之间,如果有N个线程在get操作获取到相同的oldExpireTime后,然后都去getset,假设第1个线程获取锁成功,其他锁获取失败,但是获取锁失败的线程它发起的getset命令确实执行了,这样会不会造成第一个获取锁的线程设置的锁超时时间一直在延长???
我认为这套方案确实存在这个问题的可能。但我个人认为这个微笑的误差是可以忽略的,不过技术方案上存在缺陷,大家可以自行抉择哈。
11.4 zookkeeper分布式锁
客户端调用create()方法创建名为“locknode/guid-lock-”的节点,需要注意的是,这里节点的创建类型需要设置为EPHEMERAL_SEQUENTIAL。
客户端调用getChildren(“locknode”)方法来获取所有已经创建的子节点,同时在这个节点上注册上子节点变更通知的Watcher。
客户端获取到所有子节点path之后,如果发现自己在步骤1中创建的节点是所有节点中序号最小的,那么就认为这个客户端获得了锁。
如果在步骤3中发现自己并非是所有子节点中最小的,说明自己还没有获取到锁,就开始等待,直到下次子节点变更通知的时候,再进行子节点的获取,判断是否获取锁。
11.5 Redisson 分布式锁实现分析
获取锁
首先尝试获取锁,具体代码下面再看,返回结果是已存在的锁的剩余存活时间,为
null则说明没有已存在的锁并成功获得锁。如果获得锁则结束流程,回去执行业务逻辑。
如果没有获得锁,则需等待锁被释放,并通过 Redis 的 channel 订阅锁释放的消息,这里的具体实现本文也不深入,只是简单提一下 Redisson 在执行 Redis 命令时提供了同步和异步的两种实现,但实际上同步的实现都是基于异步的,具体做法是使用 Netty 中的异步工具 Future 和 FutureListener 结合 JDK 中的 CountDownLatch 一起实现。
订阅锁的释放消息成功后,进入一个不断重试获取锁的循环,循环中每次都先试着获取锁,并得到已存在的锁的剩余存活时间。
如果在重试中拿到了锁,则结束循环,跳过第 6 步。
如果锁当前是被占用的,那么等待释放锁的消息,具体实现使用了 JDK 并发的信号量工具 Semaphore 来阻塞线程,当锁释放并发布释放锁的消息后,信号量的
release()方法会被调用,此时被信号量阻塞的等待队列中的一个线程就可以继续尝试获取锁了。在成功获得锁后,就没必要继续订阅锁的释放消息了,因此要取消对 Redis 上相应 channel 的订阅。
释放锁
- 使用
EVAL命令执行 Lua 脚本来释放锁: - key 不存在,说明锁已释放,直接执行
publish命令发布释放锁消息并返回1。 - key 存在,但是 field 在 Hash 中不存在,说明自己不是锁持有者,无权释放锁,返回
nil。 - 因为锁可重入,所以释放锁时不能把所有已获取的锁全都释放掉,一次只能释放一把锁,因此执行
hincrby对锁的值减一。 - 释放一把锁后,如果还有剩余的锁,则刷新锁的失效时间并返回
0;如果刚才释放的已经是最后一把锁,则执行del命令删除锁的 key,并发布锁释放消息,返回1。 - 上面执行结果返回
nil的情况(即第2中情况),因为自己不是锁的持有者,不允许释放别人的锁,故抛出异常。 - 执行结果返回
1的情况,该锁的所有实例都已全部释放,所以不需要再刷新锁的失效时间。
作者:Raymond_Z
链接:https://www.jianshu.com/p/de5a69622e49
十二 JMX
https://juejin.im/post/6856949531003748365
十三 Redis
13.1 redis持久化
Redis是一个支持持久化的内存数据库,通过持久化机制把内存中的数据同步到硬盘文件来保证数据持久化。当Redis重启后通过把硬盘文件重新加载到内存,就能达到恢复数据的目的。
实现:单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,然后由子进程写入到临时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存释放。
RDB是Redis默认的持久化方式。按照一定的时间周期策略把内存的数据以快照的形式保存到硬盘的二进制文件。即Snapshot快照存储,对应产生的数据文件为dump.rdb,通过配置文件中的save参数来定义快照的周期。( 快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。)
AOF:Redis会将每一个收到的写命令都通过Write函数追加到文件最后,类似于MySQL的binlog。当Redis重启是会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
13.2 缓存问题
缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级等问题
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间
(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决办法:
大多数系统设计者考虑用加锁( 最多的解决方案)或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开。
二、缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决办法;
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
5TB的硬盘上放满了数据,请写一个算法将这些数据进行排重。如果这些数据是一些32bit大小的数据该如何解决?如果是64bit的呢?
对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。
Bitmap: 典型的就是哈希表
缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
布隆过滤器(推荐)
就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
受提醒补充:缓存穿透与缓存击穿的区别
缓存击穿:指一个key非常热点,大并发集中对这个key进行访问,当这个key在失效的瞬间,仍然持续的大并发访问就穿破缓存,转而直接请求数据库。
解决方案;在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。
十四 springcloud
14.1 五大组件
- 服务发现——Netflix Eureka客服端
- 负载均衡——Netflix Ribbon
- 断路器——Netflix Hystrix
- 服务网关——Netflix Zuul
- 分布式配置——Spring Cloud Config
14.2 什么是 spring cloud?
spring cloud 是一系列框架的有序集合。它利用 spring boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 spring boot 的开发风格做到一键启动和部署。
14.3 spring cloud 断路器的作用是什么?
在分布式架构中,断路器模式的作用也是类似的,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
14.4 什么是服务熔断?什么是服务降级
在复杂的分布式系统中,微服务之间的相互调用,有可能出现各种各样的原因导致服务的阻塞,在高并发场景下,服务的阻塞意味着线程的阻塞,导致当前线程不可用,服务器的线程全部阻塞,导致服务器崩溃,由于服务之间的调用关系是同步的,会对整个微服务系统造成服务雪崩
为了解决某个微服务的调用响应时间过长或者不可用进而占用越来越多的系统资源引起雪崩效应就需要进行服务熔断和服务降级处理。
所谓的服务熔断指的是某个服务故障或异常一起类似显示世界中的“保险丝”当某个异常条件被触发就直接熔断整个服务,而不是一直等到此服务超时。
服务熔断就是相当于我们电闸的保险丝,一旦发生服务雪崩的,就会熔断整个服务,通过维护一个自己的线程池,当线程达到阈值的时候就启动服务降级,如果其他请求继续访问就直接返回fallback的默认值
14.5 Eureka和ZooKeeper的区别
1.ZooKeeper保证的是CP,Eureka保证的是AP
选择可用性 A(Availability),此时,那个失去联系的节点依然可以向系统提供服务,不过它的数据就不能保证是同步的了(失去了C属性)。
选择一致性C(Consistency),为了保证数据库的一致性,我们必须等待失去联系的节点恢复过来,在这个过程中,那个节点是不允许对外提供服务的,这时候系统处于不可用状态(失去了A属性)。最常见的例子是读写分离,某个节点负责写入数据,然后将数据同步到其它节点,其它节点提供读取的服务,当两个节点出现通信问题时,你就面临着选择A(继续提供服务,但是数据不保证准确),C(用户处于等待状态,一直等到数据同步完成)。
ZooKeeper在选举期间注册服务瘫痪,虽然服务最终会恢复,但是选举期间不可用的
Eureka各个节点是平等关系,只要有一台Eureka就可以保证服务可用,而查询到的数据并不是最新的。自我保护机制会导致Eureka不再从注册列表移除因长时间没收到心跳而应该过期的服务Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点(高可用),当网络稳定时,当前实例新的注册信息会被同步到其他节点中(最终一致性),Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像ZooKeeper一样使得整个注册系统瘫痪
2.ZooKeeper有Leader和Follower角色,Eureka各个节点平等
3.ZooKeeper采用过半数存活原则,Eureka采用自我保护机制解决分区问题
4.Eureka本质上是一个工程,而ZooKeeper只是一个进程
14.6 Ribbon和Feign的区别?
1.Ribbon都是调用其他服务的,但方式不同。
2.启动类注解不同,Ribbon是@RibbonClient feign的是@EnableFeignClients
3.服务指定的位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
4.调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。Feign需要将调用的方法定义成抽象方法即可。